source:
realpython.com
source:
realpython.com
Project Overview
Digital Talend Scholarship (DTS) adalah program pelatihan pengembangan kompetensi yang telah diberikan kepada talenta digital Indonesia sejak tahun 2018. Program ini ditunjukan untuk meningkatkan keterampilan dan daya saing, produktivitas, profesionalisme SDM bidang teknologi informasi dan komunikasi bagi angkatan kerja muda Indonesia, masyarakat umum, dan aparatur sipil negaradi bidang Komunikasi dan Informatika sehingga dapat meningkatkan produktivitas dan daya saing bangsa di era Industri 4.0, serta mampu memenuhi kebutuhan tenaga terampil di bidang teknologi.
Mitra pelatihan yang bekerja sama yaitu DQLab. DQLab adalah platform belajar online yang berfokus pada pengenalan Data Science & Artificial Intelligence (AI) dengan menggunakan bahasa pemrograman populer seperti Python dan SQL, serta platform edukasi pertama yang mengintegrasi fitur ChatGPT & mengutamakan pembelajaran praktik langsung yang dapat diterapkan di dunia nyata.
Pada project ini menggunakan bahasa pemrograman Python dengan library Pandas untuk pengolahan data. Pandas mempermudah proses ekstraksi, transformasi, dan pemuatan (ETL) data dari berbagai sumber, memungkinkan pengelolaan data dalam jumlah besar dengan efisiensi tinggi. Data dibersihkan dan dimodifikasi sesuai kebutuhan analisis, memastikan bahwa hasil akhir akurat dan siap digunakan untuk pengambilan keputusan. Dengan Pandas, proses manipulasi data menjadi lebih cepat dan fleksibel, serta mendukung penerapan pipeline ETL yang efisien dan dapat diandalkan. Pandas juga memberikan kemampuan untuk melakukan analisis data secara mendalam, memvisualisasikan pola, dan mengidentifikasi tren penting yang dapat diimplementasikan untuk perbaikan proses bisnis.
Dataset
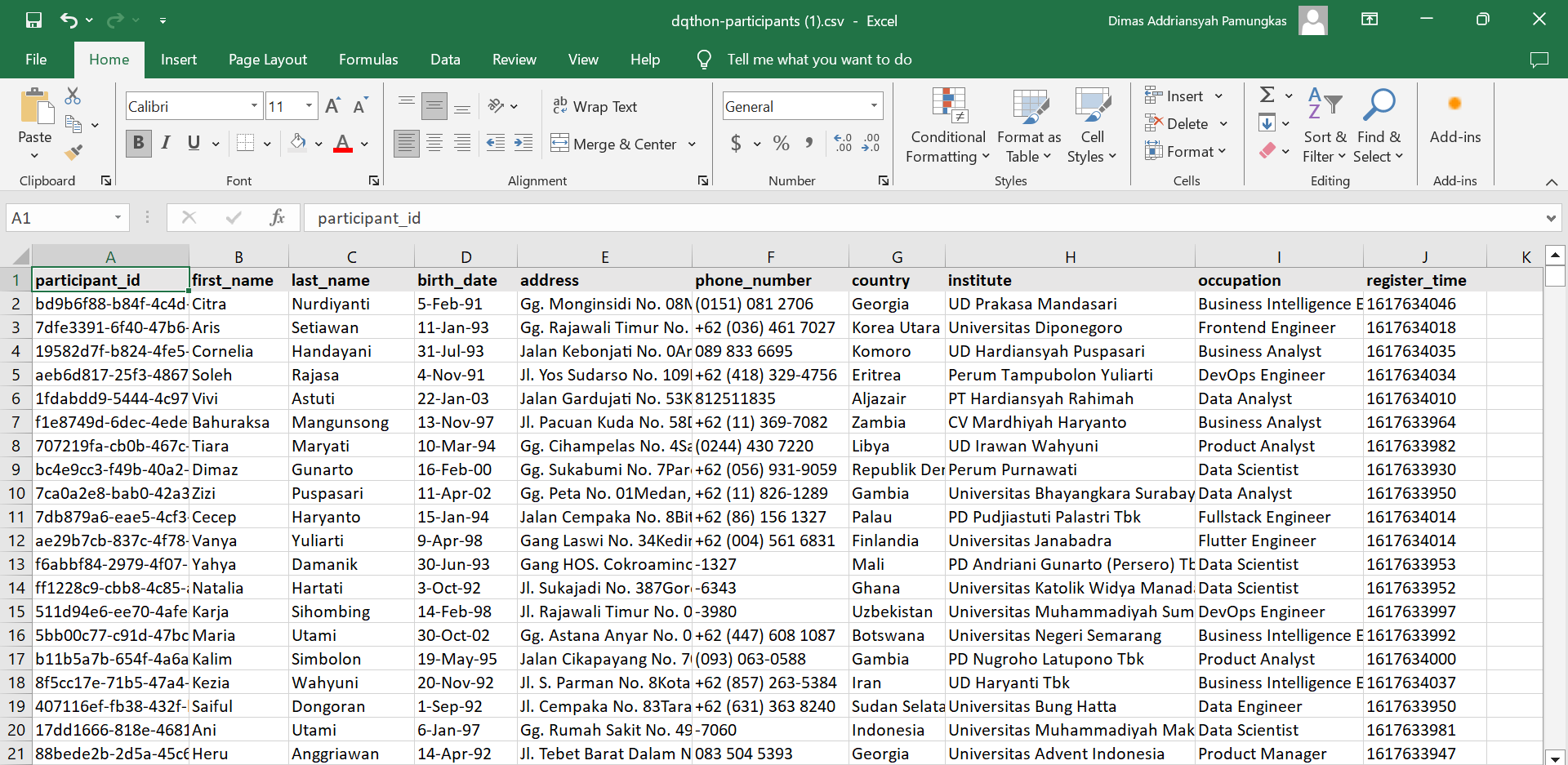
Diberikan dataset challange yang meliputi data:
| no | data | description |
|---|---|---|
| 1. | participant_id | id dari peserta/partisipan hackathon. kolom ini bersifat unique sehingga antar peserta pasti memiliki id yang berbeda |
| 2. | first_name | nama depan peserta |
| 3. | last_name | nama belakang peserta |
| 4. | birth_date | tanggal lahir peserta |
| 5. | address | alamat tempat tinggal peserta |
| 6. | phone_number | nomor hp/telepon peserta |
| 7. | country | negara asal peserta |
| 8. | institute | institusi peserta saat ini, bisa berupa nama perusahaan maupun nama universitas |
| 9. | occupation | pekerjaan peserta saat ini |
| 10. | register_time | waktu peserta melakukan pendaftaran hackathon dalam second |
Challenge
- Challenge Pertama
- Challenge Kedua
- Challenge Ketiga
- Challenge Keempat
- Challenge Kelima
- Jika awalan nomor HP berupa angka 62 atau +62 yang merupakan kode telepon Indonesia, maka diterjemahkan ke 0.
- Tidak ada tanda baca seperti kurung buka, kurung tutup, strip⟶ ()-
- Tidak ada spasi pada nomor HP dan nama kolom untuk menyimpan hasil cleansing pada nomor HP yaitu cleaned_phone_number.
- Challenge Keenam
- Challenge Ketujuh
-
Format email:
xxyy@aa.bb.[ac/com].[cc] -
Keterangan:
xx -> nama depan (first_name) dalam lowercase
yy -> nama belakang (last_name) dalam lowercase
aa -> nama institusi -
Untuk nilai bb, dan cc mengikuti nilai dari aa. Aturannya:
- Jika institusi nya merupakan Universitas, maka bb -> gabungan dari huruf pertama pada setiap kata dari nama Universitas dalam lowercase Kemudian, diikuti dengan .ac yang menandakan akademi/institusi belajar dan diikuti dengan pattern cc
- Jika institusi bukan merupakan Universitas, maka bb -> gabungan dari huruf pertama pada setiap kata dari nama Universitas dalam lowercase Kemudian, diikuti dengan .com. Perlu diketahui bahwa pattern cc tidak berlaku pada kondisi ini
-
cc -> merupakan negara asal peserta, adapun aturannya:
- Jika banyaknya kata pada negara tersebut lebih dari 1 maka ambil singkatan dari negara tersebut dalam lowercase
- Namun, jika banyaknya kata hanya 1 maka ambil 3 huruf terdepan dari negara tersebut dalam lowercase
-
Nama depan: Citra
Nama belakang: Nurdiyanti
Institusi: UD Prakasa Mandasari
Negara: Georgia
Maka Email nya: citranurdiyanti@upm.geo -
Nama depan: Aris
Nama belakang: Setiawan
Institusi: Universitas Diponegoro
Negara: Korea Utara
Maka Email nya: arissetiawan@ud.ac.ku - Challenge Kedelapan
- YYYY: 4 digit yang menandakan tahun
- DD: 2 digit yang menandakan tanggal
- MM: 2 digit yang menandakan bulan
- Contohnya yaitu: 2021–04–07
- Challenge Kesembilan
- YYYY: 4 digit yang menandakan tahun
- MM: 2 digit yang menandakan bulan
- DD: 2 digit yang menandakan tanggal
- HH: 2 digit yang menandakan jam
- mm: 2 digit yang menandakan menit
- ss: 2 digit yang menandakan detik
- Contohnya yaitu: 2021–04–07 15:10:55
Extract merupakan proses meng-ekstraksi data dari sumber, sumber data ini bisa berupa relational data (SQL) atau tabel, nonrelational (NoSQL) maupun yang lainnya.
File tersebut bisa diakses melalui URL:
https://storage.googleapis.com/dqlab-dataset/dqthon-participants.csv
Answer:
import pandas as pd
df_participant = pd.read_csv('https://storage.googleapis.com/dqlab-dataset/dqthon-participants.csv')
print(df_participant)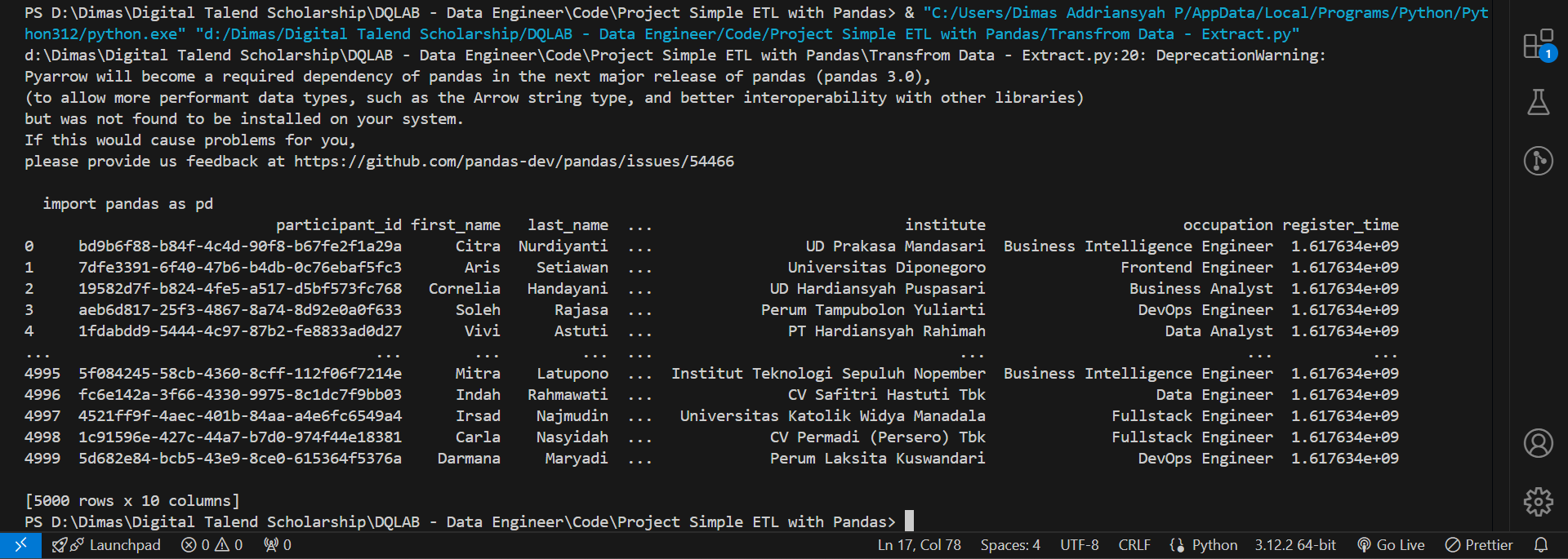
Ada permintaan datang dari tim logistik bahwa mereka membutuhkan kode pos dari peserta agar pengiriman piala lebih mudah dan cepat sampai. Maka dari itu buatlah kolom baru bernama postal_code yang memuat informasi mengenai kode pos yang diambil dari alamat peserta (kolom address). Diketahui bahwa kode pos berada di paling akhir dari alamat tersebut.
Note:
Jika regex yang dimasukkan tidak bisa menangkap pattern dari value kolom
address maka akan menghasilkan NaN.
Answer:
import pandas as pd
df_participant = pd.read_csv('https://storage.googleapis.com/dqlab-dataset/dqthon-participants.csv')
df_participant['postal_code'] = df_participant['address'].str.extract(r'(\d+)$')
print(df_participant)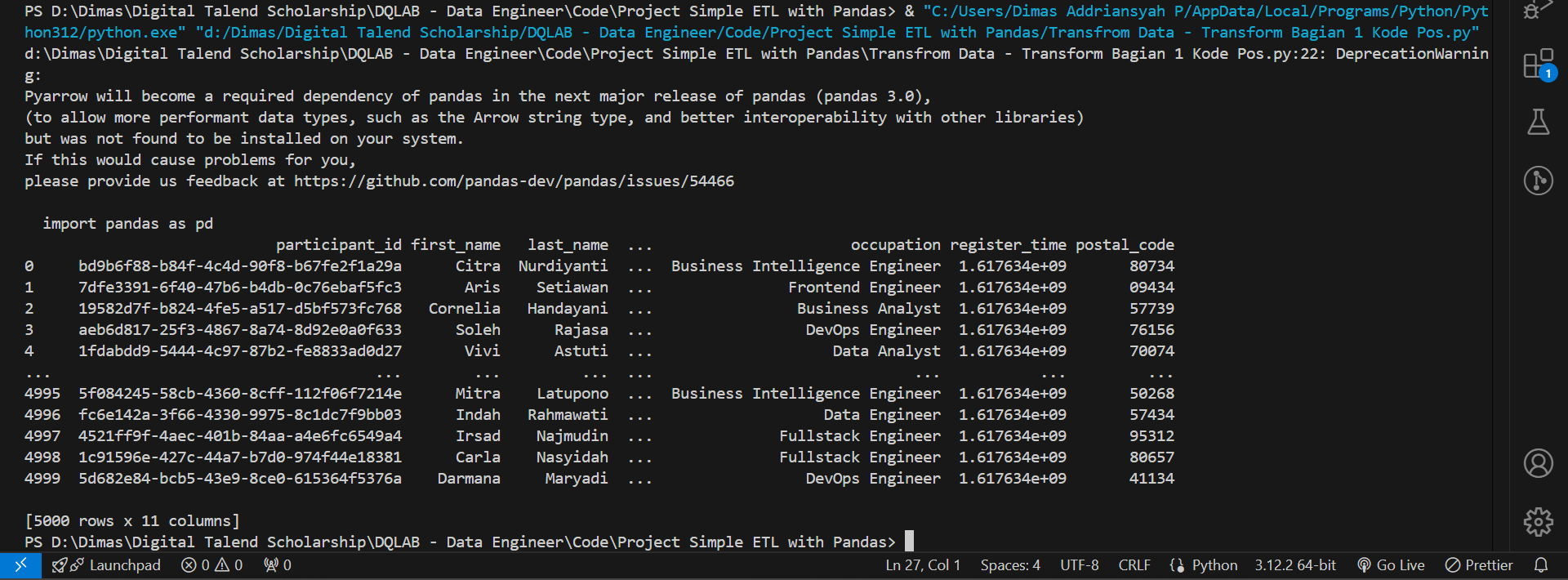
Selain kode pos, mereka juga membutuhkan kota dari peserta. Untuk menyediakan informasi tersebut, buatlah kolom baru bernama city yang didapat dari kolom address.
Diasumsikan bahwa kota merupakan sekumpulan karakter yang terdapat setelah nomor jalan diikuti dengan \n (newline character) atau dalam bahasa lainnya yaitu enter.
Answer:
import pandas as pd
df_participant = pd.read_csv('https://storage.googleapis.com/dqlab-dataset/dqthon-participants.csv')
df_participant['postal_code'] = df_participant['address'].str.extract(r'(\d+)$')
df_participant['city'] = df_participant['address'].str.extract(r'(?<=\n)(\w.+)(?=,)')
print(df_participant)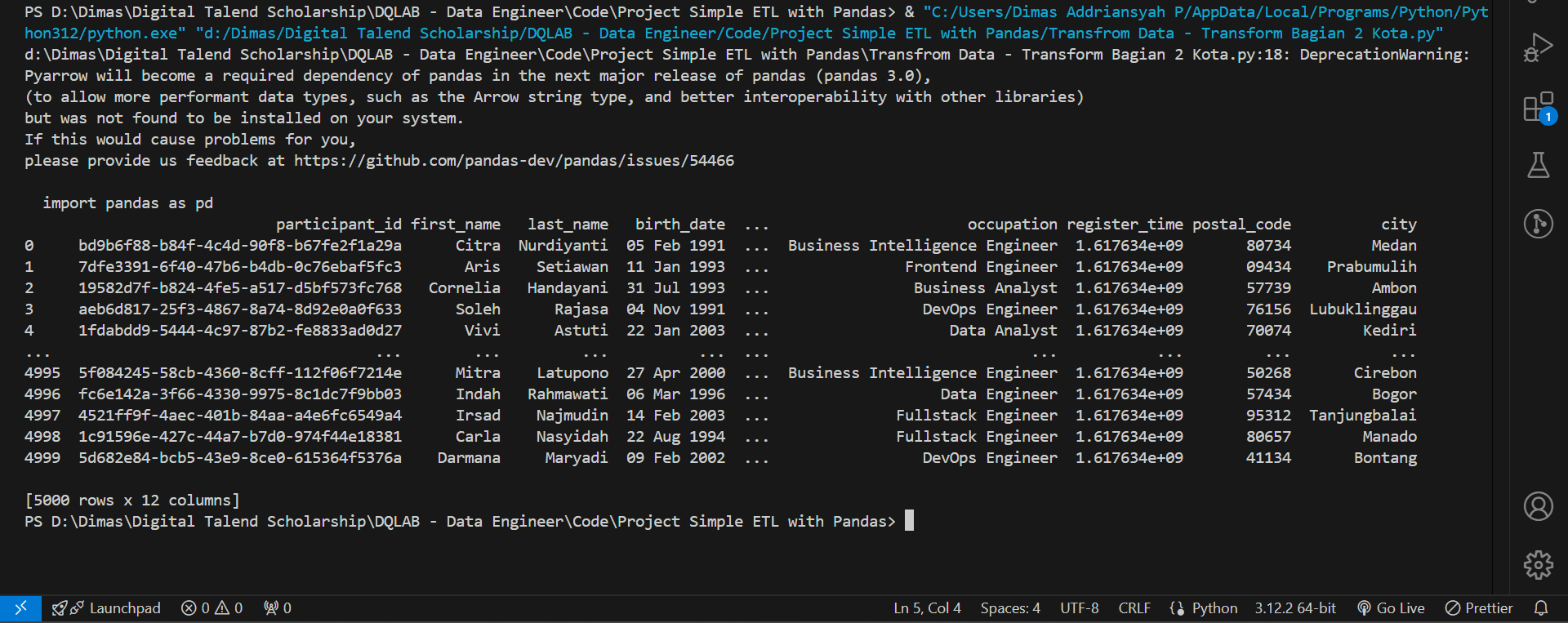
Salah satu parameter untuk mengetahui proyek apa saja yang pernah dikerjakan oleh peserta yaitu dari git repository mereka. Pada kasus ini kita menggunakan profil github sebagai parameternya. Buatlah kolom baru bernama github_profile yang merupakan link profil github dari peserta.
Diketahui bahwa profil github mereka merupakan gabungan dari first_name dan last_name yang sudah di-lowercase.
Answer:
import pandas as pd
df_participant = pd.read_csv('https://storage.googleapis.com/dqlab-dataset/dqthon-participants.csv')
df_participant['postal_code'] = df_participant['address'].str.extract(r'(\d+)$')
df_participant['city'] = df_participant['address'].str.extract(r'(?<=\n)(\w.+)(?=,)')
df_participant['github_profile'] = 'https://github.com/' + df_participant['first_name'].str.lower() + df_participant['last_name'].str.lower()
print(df_participant)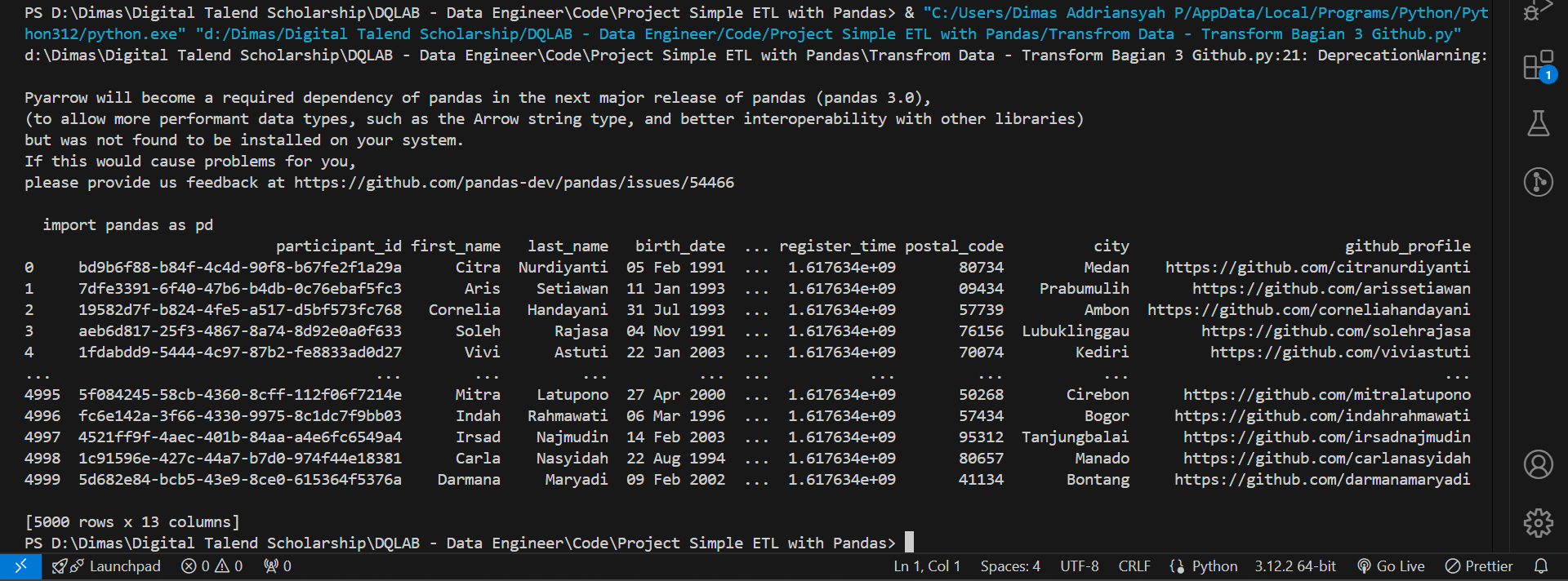
Jika kita lihat kembali, ternyata nomor handphone yang ada pada data csv kita memiliki format yang berbeda-beda. Maka dari itu, kita perlu untuk melakukan cleansing pada data nomor handphone agar memiliki format yang sama. Anda sebagai Data Engineer diberi privilege untuk menentukan format nomor handphone yang benar.
Pada kasus ini mari kita samakan formatnya dengan aturan:
Answer:
import pandas as pd
df_participant = pd.read_csv('https://storage.googleapis.com/dqlab-dataset/dqthon-participants.csv')
df_participant['postal_code'] = df_participant['address'].str.extract(r'(\d+)$')
df_participant['city'] = df_participant['address'].str.extract(r'(?<=\n)(\w.+)(?=,)')
df_participant['github_profile'] = 'https://github.com/' + df_participant['first_name'].str.lower() + df_participant['last_name'].str.lower()
df_participant['cleaned_phone_number'] = df_participant['phone_number'].str.replace(r'^(\+62|62)', '0')
df_participant['cleaned_phone_number'] = df_participant['cleaned_phone_number'].str.replace(r'[()-]', '')
df_participant['cleaned_phone_number'] = df_participant['cleaned_phone_number'].str.replace(r'\s+', '')
print(df_participant)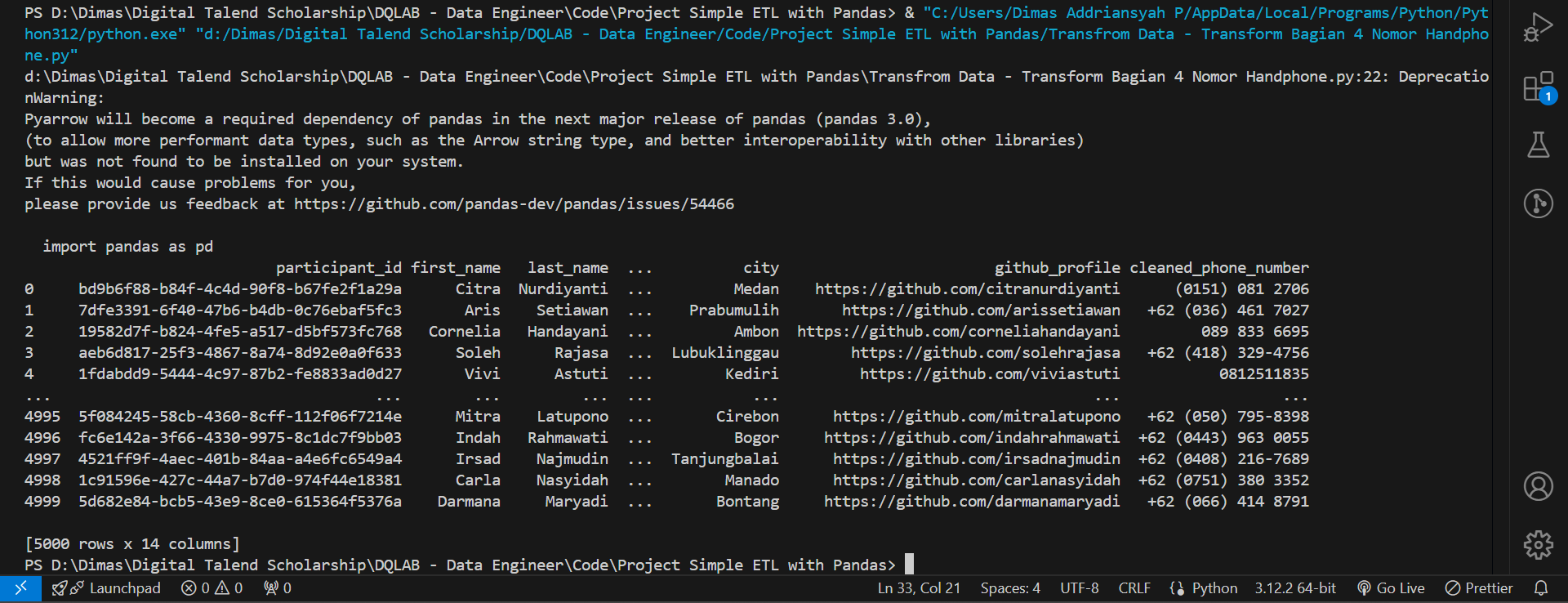
Dataset saat ini belum memuat nama tim, dan rupanya dari tim Data Analyst membutuhkan informasi terkait nama tim dari masing-masing peserta.
Diketahui bahwa nama tim merupakan gabungan nilai dari kolom first_name, last_name, country dan institute.
Buatlah kolom baru dengan nama team_name yang memuat informasi nama tim dari peserta.
Answer:
import pandas as pd
df_participant = pd.read_csv('https://storage.googleapis.com/dqlab-dataset/dqthon-participants.csv')
df_participant['postal_code'] = df_participant['address'].str.extract(r'(\d+)$')
df_participant['city'] = df_participant['address'].str.extract(r'(?<=\n)(\w.+)(?=,)')
df_participant['github_profile'] = 'https://github.com/' + df_participant['first_name'].str.lower() + df_participant['last_name'].str.lower()
df_participant['cleaned_phone_number'] = df_participant['phone_number'].str.replace(r'^(\+62|62)', '0')
df_participant['cleaned_phone_number'] = df_participant['cleaned_phone_number'].str.replace(r'[()-]', '')
df_participant['cleaned_phone_number'] = df_participant['cleaned_phone_number'].str.replace(r'\s+', '')
def func(col):
abbrev_name = "%s%s"%(col['first_name'][0],col['last_name'][0])
country = col['country']
abbrev_institute = '%s'%(''.join(list(map(lambda word: word[0], col['institute'].split()))))
return "%s-%s-%s"%(abbrev_name,country,abbrev_institute)
df_participant['team_name'] = df_participant.apply(func, axis=1)
print(df_participant)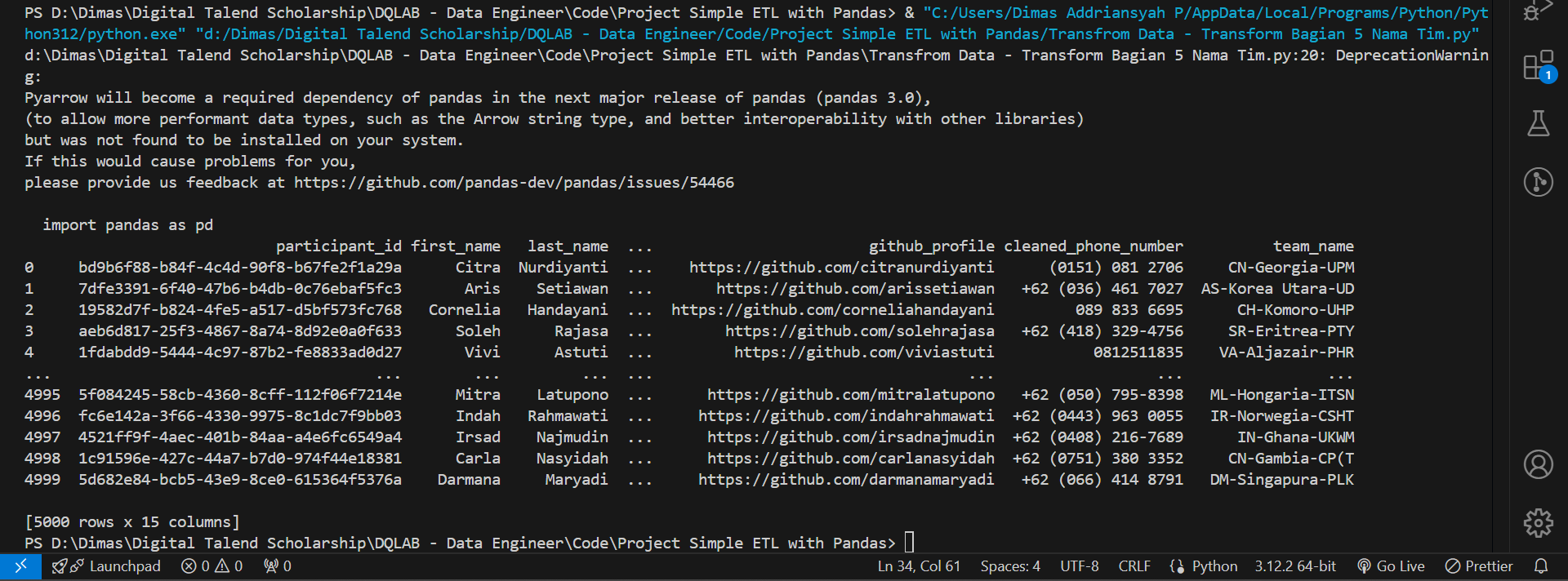
Setelah dilihat kembali dari data peserta yang dimiliki, ternyata ada satu informasi yang penting namun belum tersedia, yaitu email.
Informasi email dari peserta dengan aturan bahwa format email sebagai berikut :
Contoh:
Answer:
import pandas as pd
df_participant = pd.read_csv('https://storage.googleapis.com/dqlab-dataset/dqthon-participants.csv')
df_participant['postal_code'] = df_participant['address'].str.extract(r'(\d+)$')
df_participant['city'] = df_participant['address'].str.extract(r'(?<=\n)(\w.+)(?=,)')
df_participant['github_profile'] = 'https://github.com/' + df_participant['first_name'].str.lower() + df_participant['last_name'].str.lower()
df_participant['cleaned_phone_number'] = df_participant['phone_number'].str.replace(r'^(\+62|62)', '0')
df_participant['cleaned_phone_number'] = df_participant['cleaned_phone_number'].str.replace(r'[()-]', '')
df_participant['cleaned_phone_number'] = df_participant['cleaned_phone_number'].str.replace(r'\s+', '')
def func(col):
abbrev_name = "%s%s"%(col['first_name'][0],col['last_name'][0])
country = col['country']
abbrev_institute = '%s'%(''.join(list(map(lambda word: word[0], col['institute'].split()))))
return "%s-%s-%s"%(abbrev_name,country,abbrev_institute)
df_participant['team_name'] = df_participant.apply(func, axis=1)
def func(col):
first_name_lower = col['first_name'].lower()
last_name_lower = col['last_name'].lower()
institute = ''.join(list(map(lambda word: word[0], col['institute'].lower().split())))
if 'Universitas' in col['institute']:
if len(col['country'].split()) > 1:
country = ''.join(list(map(lambda word: word[0], col['country'].lower().split())))
else:
country = col['country'][:3].lower()
return "%s%s@%s.ac.%s"%(first_name_lower,last_name_lower,institute,country)
return "%s%s@%s.com"%(first_name_lower,last_name_lower,institute)
df_participant['email'] = df_participant.apply(func, axis=1)
print(df_participant)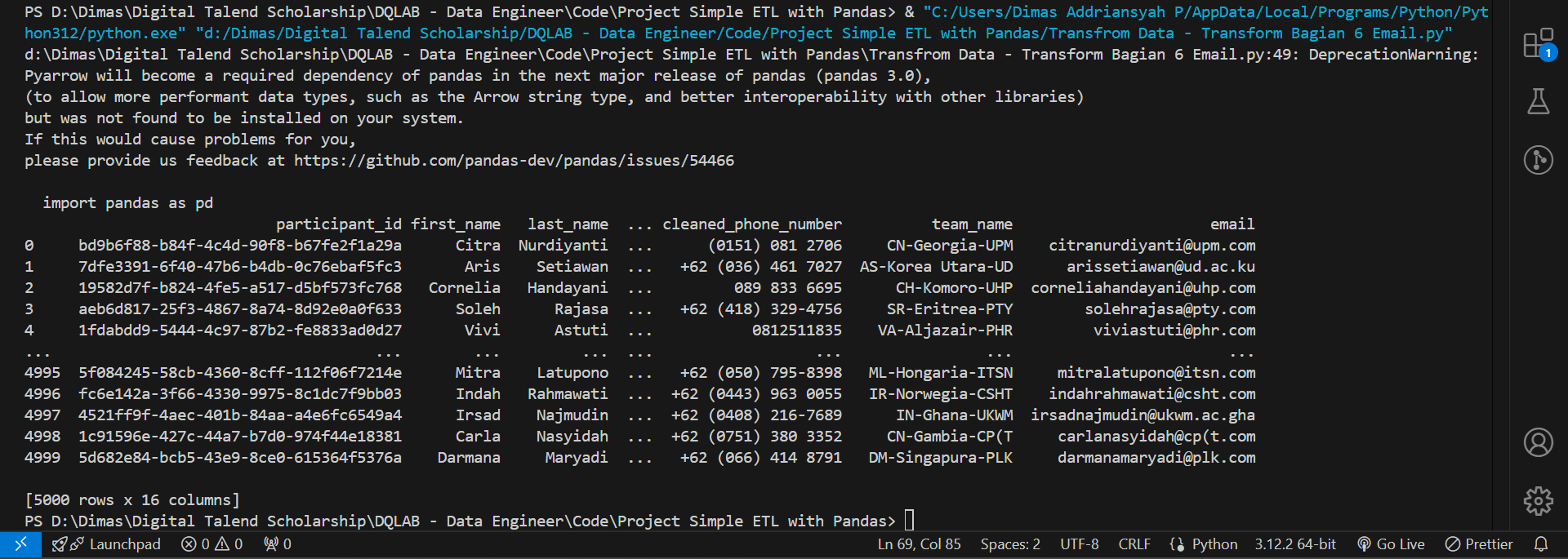
MySQL merupakan salah satu database yang sangat populer dan digunakan untuk menyimpan data berupa tabel, termasuk data hasil pengolahan yang sudah kita lakukan ini nantinya bisa dimasukkan ke MySQL.
Meskipun begitu, ada suatu aturan dari MySQL terkait format tanggal yang bisa mereka terima yaitu YYYY-MM-DD dengan keterangan:
Jika kita lihat kembali pada kolom tanggal lahir terlihat bahwa nilainya belum sesuai dengan format DATE dari MySQL Oleh karena itu, lakukanlah formatting terhadap kolom birth_date menjadi YYYY-MM-DD dan simpan di kolom yang sama.
Answer:
import pandas as pd
df_participant = pd.read_csv('https://storage.googleapis.com/dqlab-dataset/dqthon-participants.csv')
df_participant['postal_code'] = df_participant['address'].str.extract(r'(\d+)$')
df_participant['city'] = df_participant['address'].str.extract(r'(?<=\n)(\w.+)(?=,)')
df_participant['github_profile'] = 'https://github.com/' + df_participant['first_name'].str.lower() + df_participant['last_name'].str.lower()
df_participant['cleaned_phone_number'] = df_participant['phone_number'].str.replace(r'^(\+62|62)', '0')
df_participant['cleaned_phone_number'] = df_participant['cleaned_phone_number'].str.replace(r'[()-]', '')
df_participant['cleaned_phone_number'] = df_participant['cleaned_phone_number'].str.replace(r'\s+', '')
def func(col):
abbrev_name = "%s%s"%(col['first_name'][0],col['last_name'][0])
country = col['country']
abbrev_institute = '%s'%(''.join(list(map(lambda word: word[0], col['institute'].split()))))
return "%s-%s-%s"%(abbrev_name,country,abbrev_institute)
df_participant['team_name'] = df_participant.apply(func, axis=1)
def func(col):
first_name_lower = col['first_name'].lower()
last_name_lower = col['last_name'].lower()
institute = ''.join(list(map(lambda word: word[0], col['institute'].lower().split())))
if 'Universitas' in col['institute']:
if len(col['country'].split()) > 1:
country = ''.join(list(map(lambda word: word[0], col['country'].lower().split())))
else:
country = col['country'][:3].lower()
return "%s%s@%s.ac.%s"%(first_name_lower,last_name_lower,institute,country)
return "%s%s@%s.com"%(first_name_lower,last_name_lower,institute)
df_participant['email'] = df_participant.apply(func, axis=1)
df_participant['birth_date'] = pd.to_datetime(df_participant['birth_date'], format='%d %b %Y')
print(df_participant)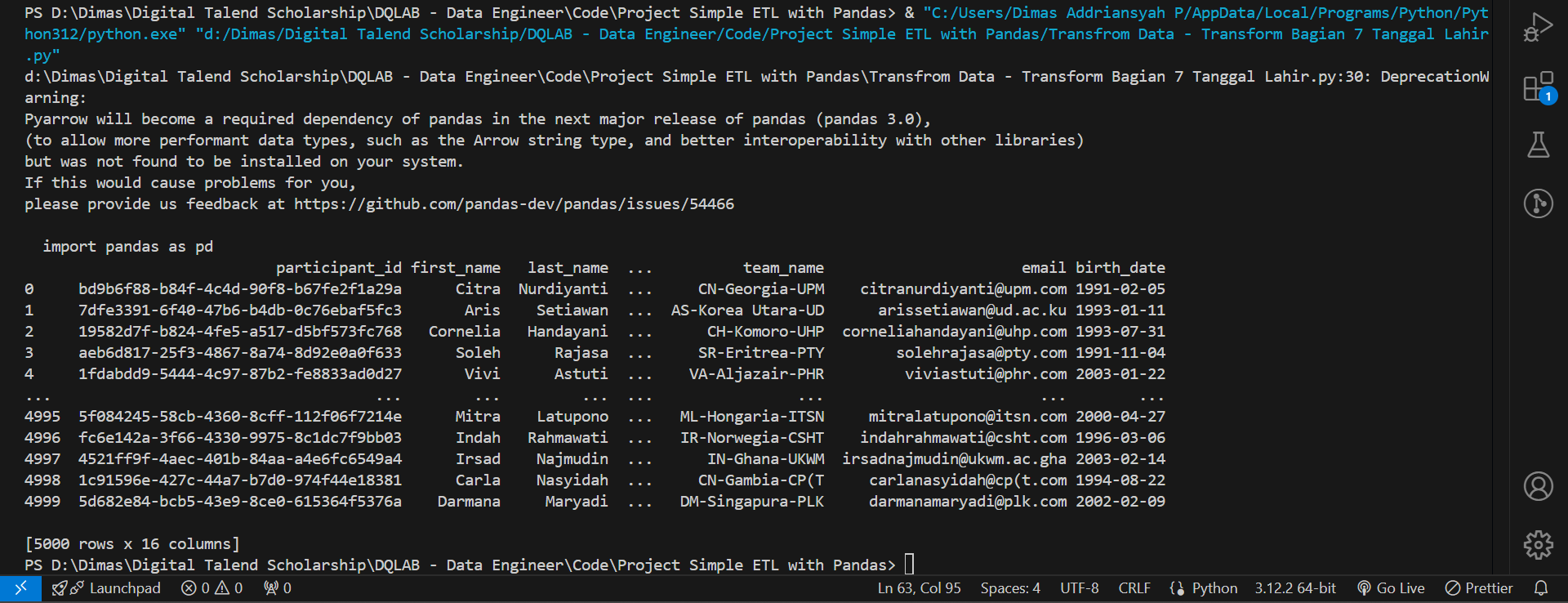
Selain punya aturan mengenai format DATE, MySQL juga memberi aturan pada data yang bertipe DATETIME yaitu YYYY-MM-DD HH:mm:ss dengan keterangan:
Karena data kita mengenai waktu registrasi peserta (register_time) belum sesuai format yang seharusnya. Maka dari itu, untuk merubah register_time ke format DATETIME sesuai dengan aturan dari MySQL. Simpanlah hasil tersebut ke kolom register_at.
Answer:
import pandas as pd
df_participant = pd.read_csv('https://storage.googleapis.com/dqlab-dataset/dqthon-participants.csv')
df_participant['postal_code'] = df_participant['address'].str.extract(r'(\d+)$')
df_participant['city'] = df_participant['address'].str.extract(r'(?<=\n)(\w.+)(?=,)')
df_participant['github_profile'] = 'https://github.com/' + df_participant['first_name'].str.lower() + df_participant['last_name'].str.lower()
df_participant['cleaned_phone_number'] = df_participant['phone_number'].str.replace(r'^(\+62|62)', '0')
df_participant['cleaned_phone_number'] = df_participant['cleaned_phone_number'].str.replace(r'[()-]', '')
df_participant['cleaned_phone_number'] = df_participant['cleaned_phone_number'].str.replace(r'\s+', '')
def func(col):
abbrev_name = "%s%s"%(col['first_name'][0],col['last_name'][0])
country = col['country']
abbrev_institute = '%s'%(''.join(list(map(lambda word: word[0], col['institute'].split()))))
return "%s-%s-%s"%(abbrev_name,country,abbrev_institute)
df_participant['team_name'] = df_participant.apply(func, axis=1)
def func(col):
first_name_lower = col['first_name'].lower()
last_name_lower = col['last_name'].lower()
institute = ''.join(list(map(lambda word: word[0], col['institute'].lower().split())))
if 'Universitas' in col['institute']:
if len(col['country'].split()) > 1:
country = ''.join(list(map(lambda word: word[0], col['country'].lower().split())))
else:
country = col['country'][:3].lower()
return "%s%s@%s.ac.%s"%(first_name_lower,last_name_lower,institute,country)
return "%s%s@%s.com"%(first_name_lower,last_name_lower,institute)
df_participant['email'] = df_participant.apply(func, axis=1)
df_participant['birth_date'] = pd.to_datetime(df_participant['birth_date'], format='%d %b %Y')
df_participant['register_at'] = pd.to_datetime(df_participant['register_time'], unit='s')
print(df_participant)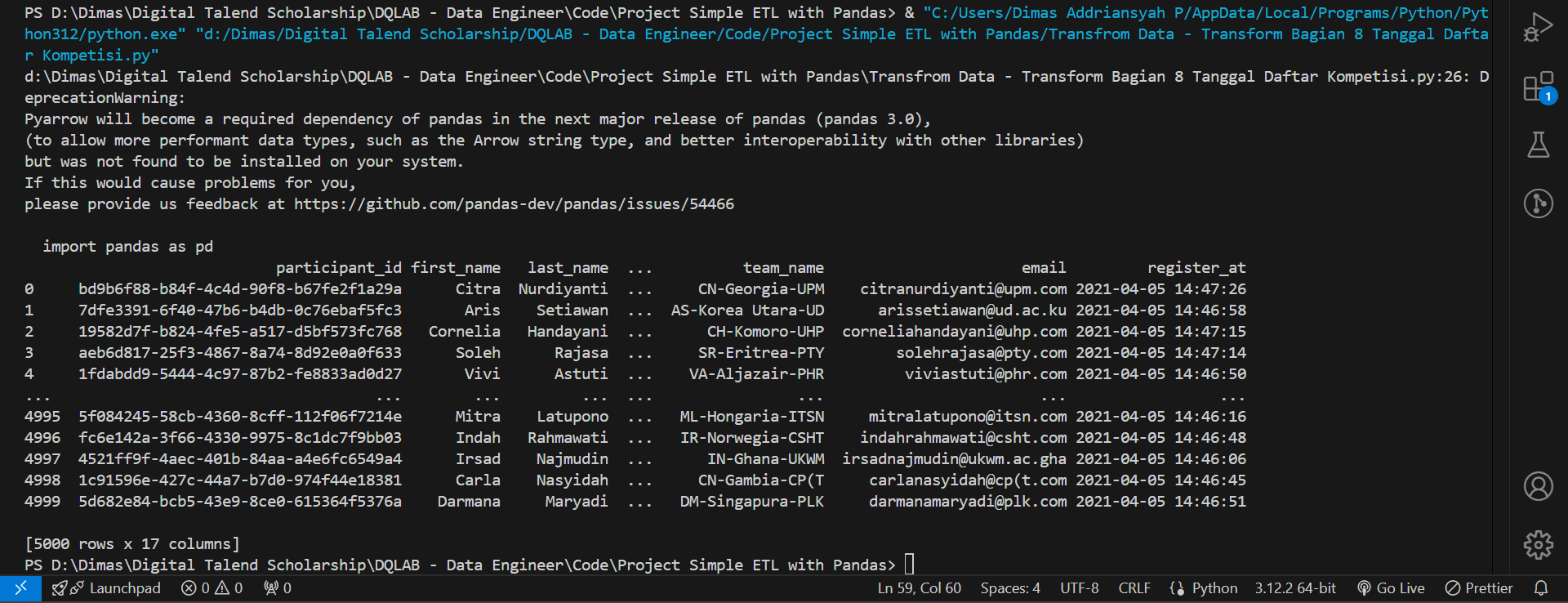
Certificate