 source:
unsplash.com
source:
unsplash.com
Project Overview
User Retention Analysis adalah proses penting yang digunakan untuk memahami perilaku pengguna terkait transaksi ulang atau penggunaan produk. Analisis ini bertujuan untuk mengidentifikasi pola dan karakteristik yang membuat pengguna tetap loyal, serta untuk menentukan faktor-faktor yang dapat meningkatkan tingkat retensi.
Keberhasilan dalam menjaga pelanggan yang sudah ada dapat memberikan dampak signifikan terhadap profitabilitas bisnis. Mempertahankan pengguna sering kali lebih efisien dibandingkan dengan menarik pengguna baru, karena pengguna yang sudah ada cenderung memiliki biaya akuisisi yang lebih rendah. Selain itu, pelanggan yang loyal biasanya akan merekomendasikan produk kepada orang lain, yang dapat meningkatkan visibilitas dan reputasi merek di pasar.
Melalui User Retention Analysis, perusahaan tidak hanya dapat mengetahui tingkat retensi pengguna, tetapi juga menggali lebih dalam mengenai alasan di balik perilaku tersebut. Analisis ini dapat mencakup penggunaan data historis untuk melihat seberapa sering pengguna kembali, seberapa lama mereka tetap aktif, dan faktor-faktor apa yang dapat mempengaruhi keputusan mereka untuk terus menggunakan produk. Dengan informasi ini, perusahaan dapat membuat keputusan strategis yang mendukung pertumbuhan jangka panjang dan menciptakan hubungan yang lebih kuat dengan pelanggan.
Pada project kali ini, business insight yang didapat antara lain yaitu:
- Pengguna paling banyak pertama kali bertransaksi pada Januari 2010 (713 Pengguna).
- Cohort pengguna tersebut juga yang paling banyak bertransaksi kembali di bulan ke-2 mereka (39% retention rate) dibanding cohort lain.
- Selain itu, cohort tersebut jugalah yang paling loyal bertransaksi selama bulan-bulan berikutnya dengan retention rate ~40%+.
- Sayangnya, sebagian besar pengguna tidak kembali bertransaksi, terlihat dari retention rate di banyak cohort dan bulan yang nilainya tak sampai 50%.
- Yang cukup mengkhawatirkan, retention rate di Desember 2010 menjadi yang terendah untuk semua cohort pengguna dibanding bulan-bulan sebelumnya.
Dataset
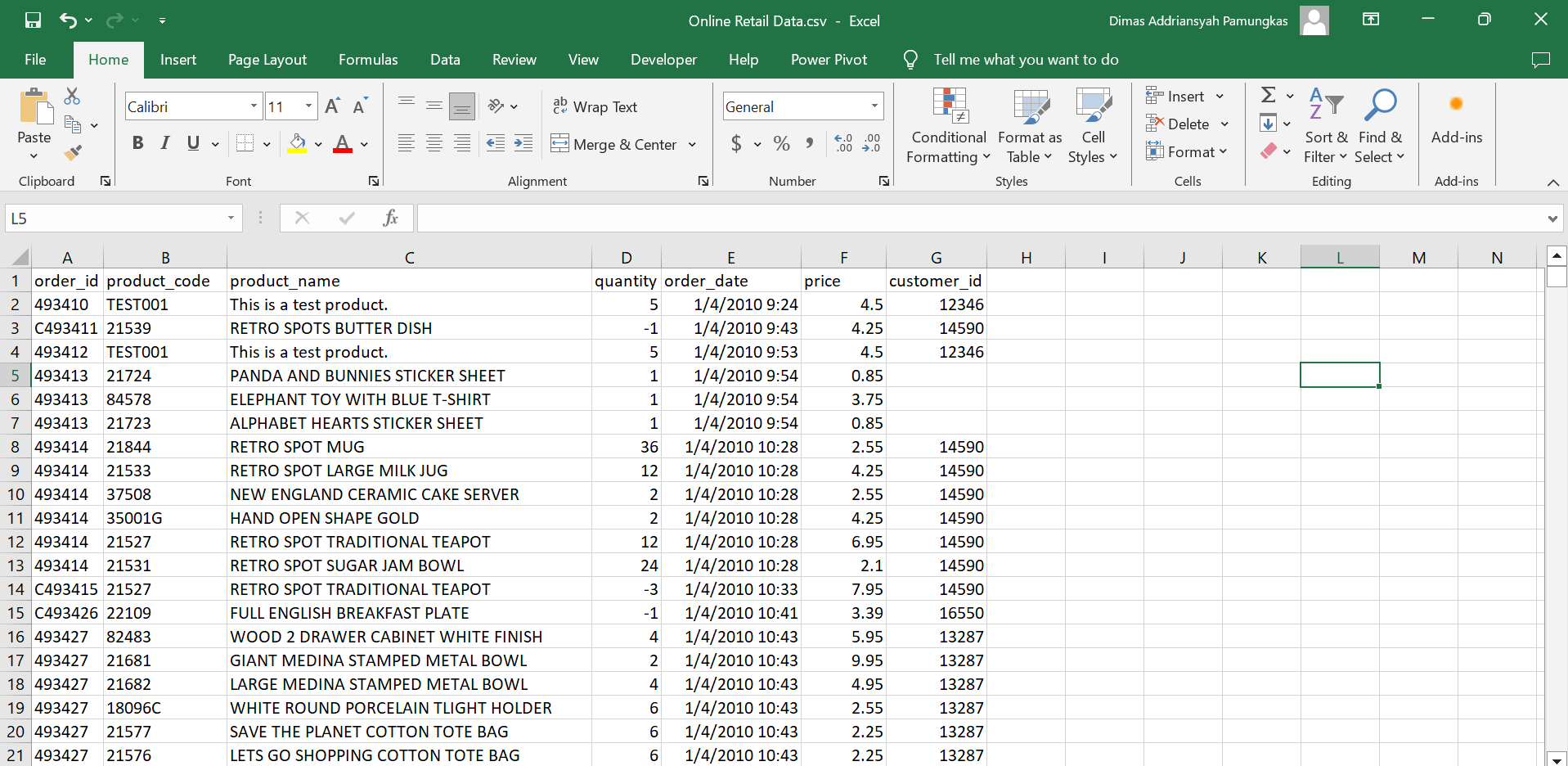
Diberikan dataset challange yang meliputi data:
| no | data | description |
|---|---|---|
| 1. | order_id | id order |
| 2. | product_id | id produk |
| 3. | product_name | nama produk |
| 4. | quantity | quantity order |
| 5. | order_date | tanggal order |
| 6. | price | harga |
| 7. | customer_id | id customer |
Explaratory Data Analysis (EDA)
- Import Data
- Data Cleansing
- Cohort Analysis
Setelah memperoleh sebuah dataset dalam format CSV, langkah selanjutnya adalah meng-import data tersebut ke dalam Python menggunakan berbagai library yang dirancang khusus untuk Analisis dan Visualisasi Data.
import pandas as pd
import numpy as np
import datetime as dt
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import seaborn as sns
from scipy import stats
from operator import attrgetter
df = pd.read_csv('../Data/Online Retail Data.csv')
df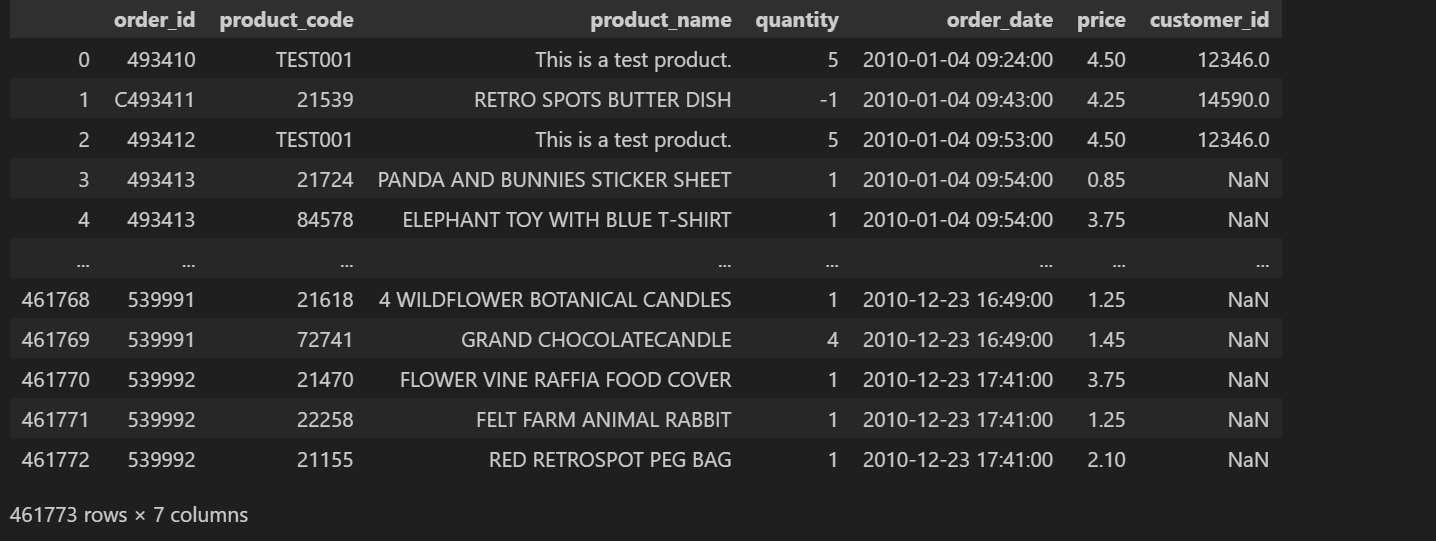
Setelah mengimpor data dan memanfaatkan berbagai library untuk analisis, langkah berikutnya adalah melakukan Data Cleansing. Proses ini sangat penting untuk memastikan bahwa data yang digunakan bebas dari kesalahan dan inkonsistensi, sehingga menghasilkan analisis yang akurat dan dapat diandalkan. Dengan membersihkan data, setiap elemen informasi dapat dimanfaatkan secara optimal, memudahkan identifikasi tren dan pola yang berharga dalam pengambilan keputusan.
df.info()
Dalam proses data cleansing, perlu diperhatikan adanya missing values dan tipe data yang salah. Untuk memastikan data menjadi akurat dan dapat diandalkan, langkah pertama adalah mengidentifikasi data yang hilang. Setelah ditemukan, langkah selanjutnya adalah menangani missing values tersebut, baik dengan menggantinya menggunakan metode imputasi seperti nilai rata-rata, median, atau modus, atau dengan menghapus baris atau kolom yang terlalu banyak kehilangan data. Selain itu, penting untuk memperbaiki tipe data yang tidak sesuai, seperti mengonversi string menjadi format tanggal atau angka. Dengan melalui proses ini, data yang bersih dan terstruktur akan diperoleh, yang pada gilirannya meningkatkan kualitas analisis dan memungkinkan pengambilan keputusan yang lebih baik.
df_clean = df.copy()
# mengkonversi kolom order_date menjadi datetime
df_clean['order_date'] = df_clean['order_date'].astype('datetime64[ns]')
# membuat kolom year_month
df_clean['year_month'] = df_clean['order_date'].dt.to_period('M')
# menghapus semua baris tanpa customer_id
df_clean = df_clean[~df_clean['customer_id'].isna()]
# menghapus semua baris tanpa product_name
df_clean = df_clean[~df_clean['product_name'].isna()]
# membuat semua product_name berhuruf kecil
df_clean['product_name'] = df_clean['product_name'].str.lower()
# menghapus semua baris dengan product_code atau product_name test
df_clean = df_clean[(~df_clean['product_code'].str.lower().str.contains('test')) |
(~df_clean['product_name'].str.contains('test '))]
# membuat kolom order_status dengan nilai 'cancelled' jika order_id diawali dengan huruf 'c' dan 'delivered' jika order_id tanpa awalan huruf 'c'
df_clean['order_status'] = np.where(df_clean['order_id'].str[:1]=='C', 'cancelled', 'delivered')
# mengubah nilai quantity yang negatif menjadi positif karena nilai negatif tersebut hanya menandakan order tersebut cancelled
df_clean['quantity'] = df_clean['quantity'].abs()
# menghapus baris dengan price bernilai negatif
df_clean = df_clean[df_clean['price']>0]
# membuat nilai amount, yaitu perkalian antara quantity dan price
df_clean['amount'] = df_clean['quantity'] * df_clean['price']
# mengganti product_name dari product_code yang memiliki beberapa product_name dengan salah satu product_name-nya yang paling sering muncul
most_freq_product_name = df_clean.groupby(['product_code','product_name'], as_index=False).agg(order_cnt=('order_id','nunique')).sort_values(['product_code','order_cnt'], ascending=[True,False])
most_freq_product_name['rank'] = most_freq_product_name.groupby('product_code')['order_cnt'].rank(method='first', ascending=False)
most_freq_product_name = most_freq_product_name[most_freq_product_name['rank']==1].drop(columns=['order_cnt','rank'])
df_clean = df_clean.merge(most_freq_product_name.rename(columns={'product_name':'most_freq_product_name'}), how='left', on='product_code')
df_clean['product_name'] = df_clean['most_freq_product_name']
df_clean = df_clean.drop(columns='most_freq_product_name')
# mengkonversi customer_id menjadi string
df_clean['customer_id'] = df_clean['customer_id'].astype(str)
# menghapus outlier
df_clean = df_clean[(np.abs(stats.zscore(df_clean[['quantity','amount']]))<3).all(axis=1)]
df_clean = df_clean.reset_index(drop=True)
df_clean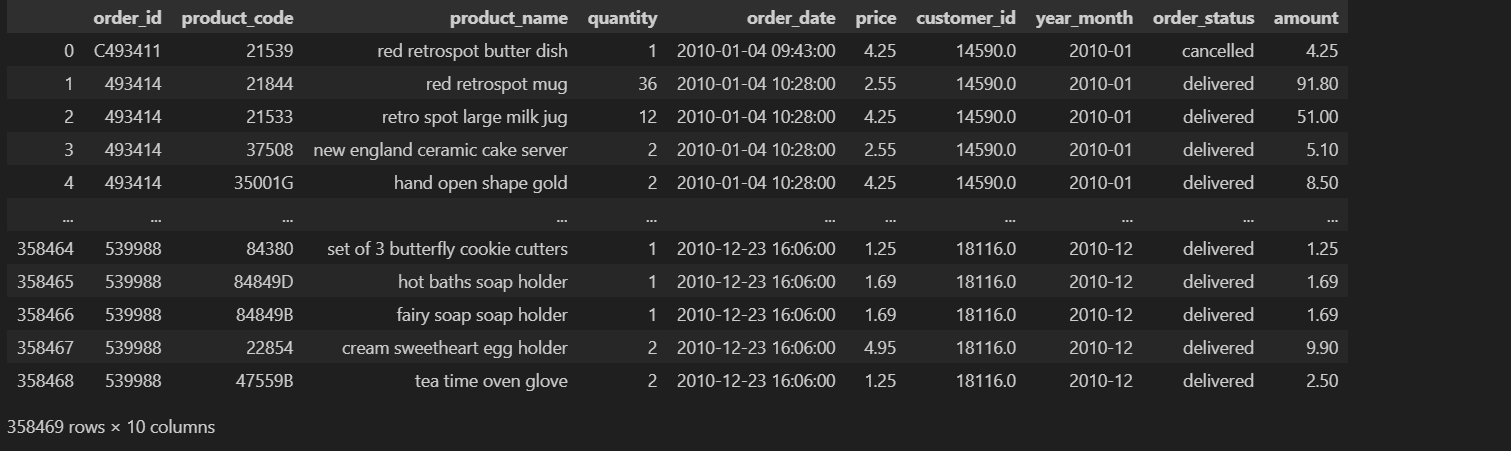
Setelah proses data cleansing dilakukan, hasilnya menunjukkan bahwa dataset kini telah dibersihkan dari missing values dan tipe data yang tidak sesuai. Data yang sebelumnya bermasalah telah diperbaiki, sehingga kini lebih konsisten dan terstruktur dengan baik.
df_clean.info()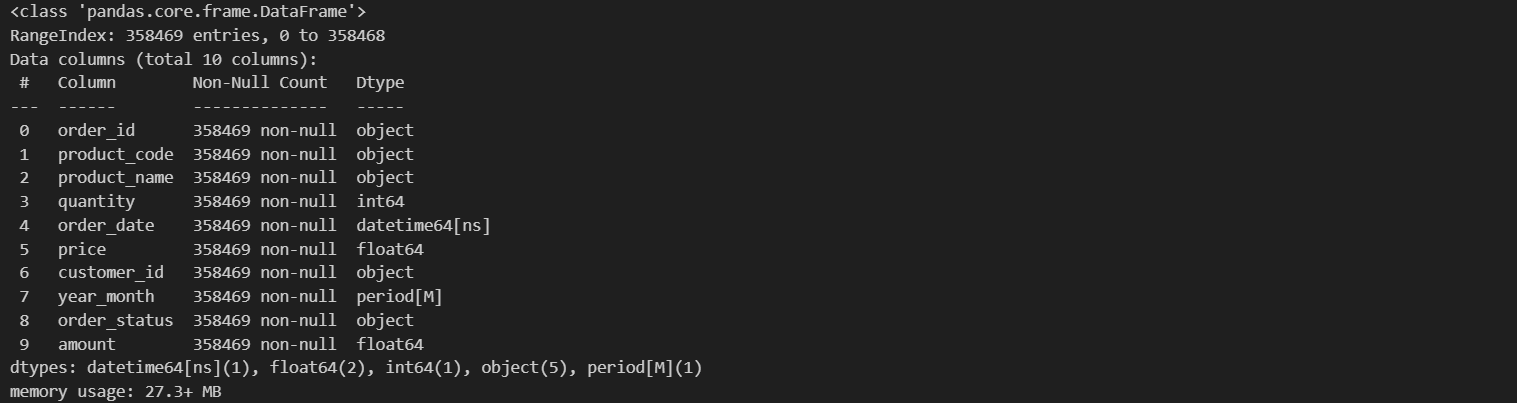
Tahap terakhir dalam proses cleansing adalah melakukan pengecekan ulang untuk memastikan tidak ada missing values atau tipe data yang salah dalam dataset. Pada langkah ini, data akan diperiksa dengan teliti untuk mengidentifikasi jika masih ada elemen yang terlewat atau tidak sesuai. Dengan melakukan pengecekan ini, keakuratan dan integritas data dapat dipastikan, sehingga analisis yang dilakukan selanjutnya memiliki dasar yang solid. Jika ditemukan masalah, langkah perbaikan dapat diambil lagi untuk menjamin bahwa data yang digunakan adalah data yang bersih dan dapat diandalkan.
Proses agregasi data transaksi dimulai dengan menyusun ringkasan total transaksi atau order setiap pengguna setiap bulan. Dalam kode tersebut, data yang telah dibersihkan dikelompokkan berdasarkan ID pelanggan dan bulan yang telah ditentukan. Dengan menggunakan fungsi agregasi, jumlah unik dari ID order dihitung untuk setiap kombinasi pelanggan dan bulan, sehingga menghasilkan dataframe baru yang menampilkan total order yang dilakukan oleh setiap pengguna dalam setiap bulan. Hasil akhir memberikan gambaran jelas mengenai aktivitas transaksi pengguna secara bulanan.
df_user_monthly = df_clean.groupby(['customer_id','year_month'], as_index=False).agg(order_cnt=('order_id','nunique'))
df_user_monthly
Untuk menganalisis perilaku pengguna secara lebih mendalam, dapat dibuat kolom baru yang mencerminkan cohort pengguna, yaitu bulan pertama kali mereka melakukan transaksi. Dengan menggunakan metode pengelompokan berdasarkan customer_id, kolom baru dapat ditambahkan ke dalam dataframe df_user_monthly yang menunjukkan bulan pertama transaksi setiap pengguna. Dalam kode tersebut, fungsi transform('min') digunakan untuk mendapatkan nilai minimum dari kolom year_month, yang merepresentasikan bulan pertama bagi masing-masing pengguna. Hasilnya adalah dataframe yang sekarang mencakup informasi mengenai cohort pengguna, memungkinkan analisis lebih lanjut terkait pola dan tren dalam perilaku mereka.
df_user_monthly['cohort'] = df_user_monthly.groupby('customer_id')['year_month'].transform('min')
df_user_monthly
Langkah selanjutnya adalah menghitung jarak bulan antara bulan transaksi dengan bulan pertama kali transaksi untuk setiap pengguna. Dengan melakukan perhitungan ini, jarak bulan yang dihasilkan akan mencerminkan berapa lama pengguna telah bertransaksi sejak bulan pertama. Untuk memastikan bahwa jarak bulan yang bernilai 0 diinterpretasikan sebagai bulan pertama, penambahan 1 dilakukan pada hasil perhitungan. Kode yang digunakan untuk mencapai hal ini menciptakan kolom baru dalam dataframe, di mana setiap nilai mencerminkan periode bulan yang benar, memberikan wawasan lebih dalam mengenai durasi hubungan pengguna dengan produk atau layanan. Hasil akhir dari proses ini ditampilkan dalam dataframe yang telah diperbarui.
df_user_monthly['period_num'] = (df_user_monthly['year_month'] - df_user_monthly['cohort']).apply(attrgetter('n')) + 1
df_user_monthly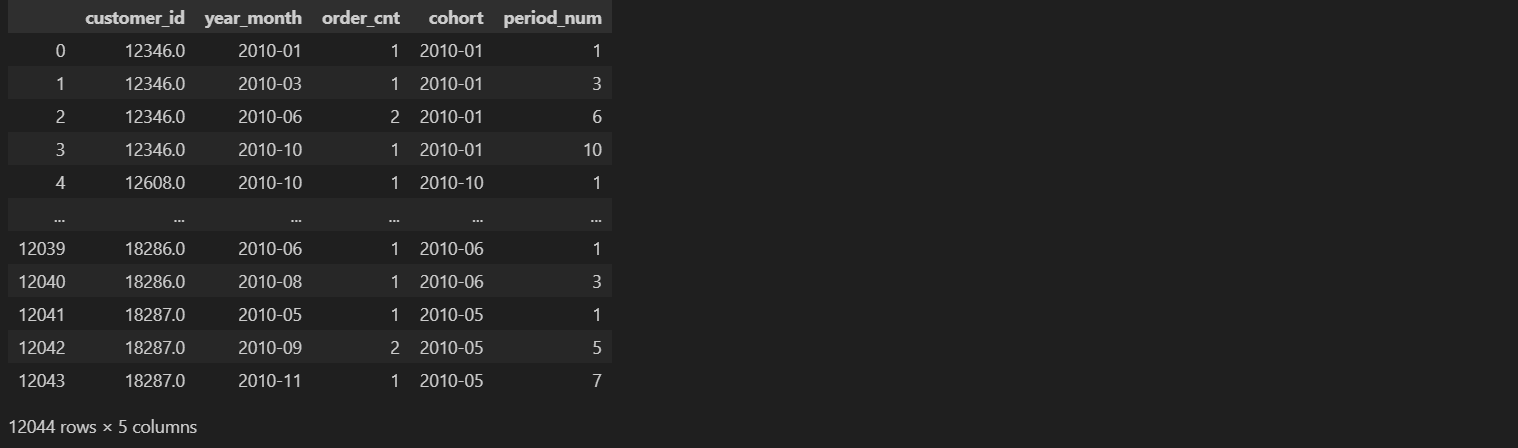
Tabel pivot dapat dibuat dengan menggunakan indeks berupa cohort, kolom yang menunjukkan jarak bulan, dan nilai yang merepresentasikan jumlah pengguna unik, yaitu hasil penghitungan jumlah unik dari ID pengguna. Proses ini dilakukan dengan memanfaatkan fungsi pd.pivot_table pada dataframe yang berisi data bulanan pengguna. Dengan mengatur parameter yang tepat, tabel pivot akan menyajikan informasi yang jelas mengenai jumlah pengguna unik untuk setiap cohort di setiap periode bulan, sehingga memudahkan analisis dan pemahaman terhadap perilaku pengguna dari waktu ke waktu. Hasil akhir dari tabel ini memberikan gambaran yang lebih mendalam tentang dinamika pengguna dalam setiap cohort yang dianalisis.
df_cohort_pivot = pd.pivot_table(df_user_monthly, index='cohort', columns='period_num', values='customer_id', aggfunc=pd.Series.nunique)
df_cohort_pivot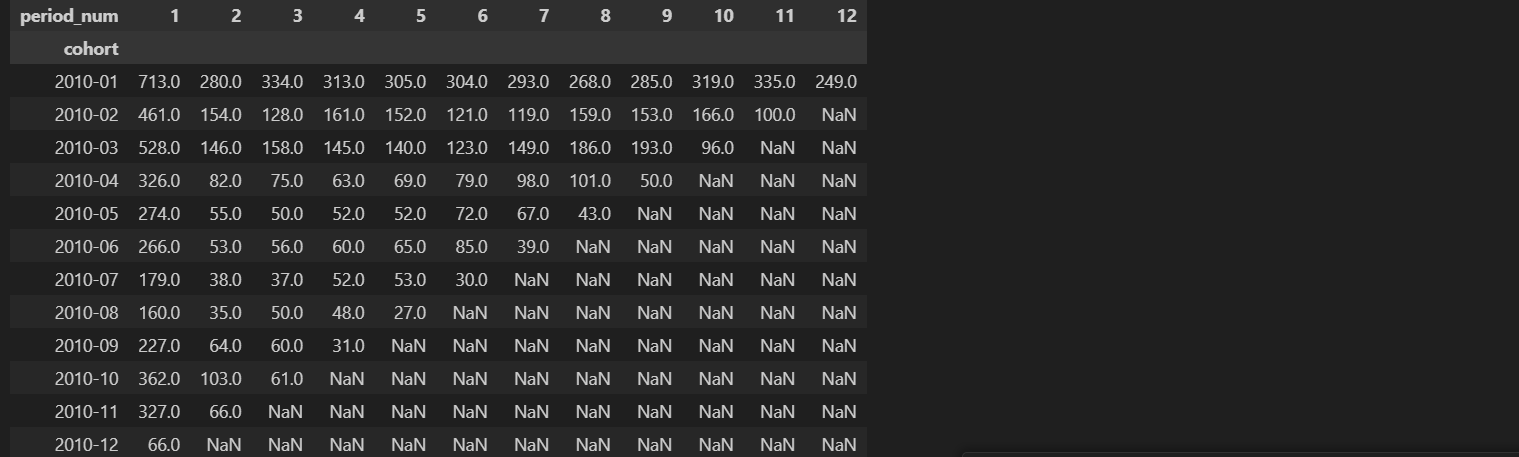
Untuk menghitung jumlah pengguna dalam setiap cohort, yaitu pengguna yang melakukan transaksi pertama kali di bulan tertentu, langkah pertama adalah mengidentifikasi cohort size dari tabel pivot yang telah dibuat sebelumnya. Setelah mendapatkan jumlah pengguna di setiap cohort, langkah selanjutnya adalah menghitung retention rate dengan membagi semua nilai dalam tabel pivot tersebut dengan jumlah pengguna yang ada di cohort. Dengan cara ini, diperoleh persentase pengguna yang kembali melakukan transaksi dalam setiap periode, memberikan wawasan yang berharga mengenai tingkat retensi pengguna dari waktu ke waktu.
cohort_size = df_cohort_pivot.iloc[:, 0]
cohort_size
Lorem ipsum dolor sit amet consectetur adipisicing elit. Libero placeat ipsum repellendus rerum repudiandae magni impedit vitae voluptatum dicta labore.
df_retention_cohort = df_cohort_pivot.divide(cohort_size, axis=0)
df_retention_cohort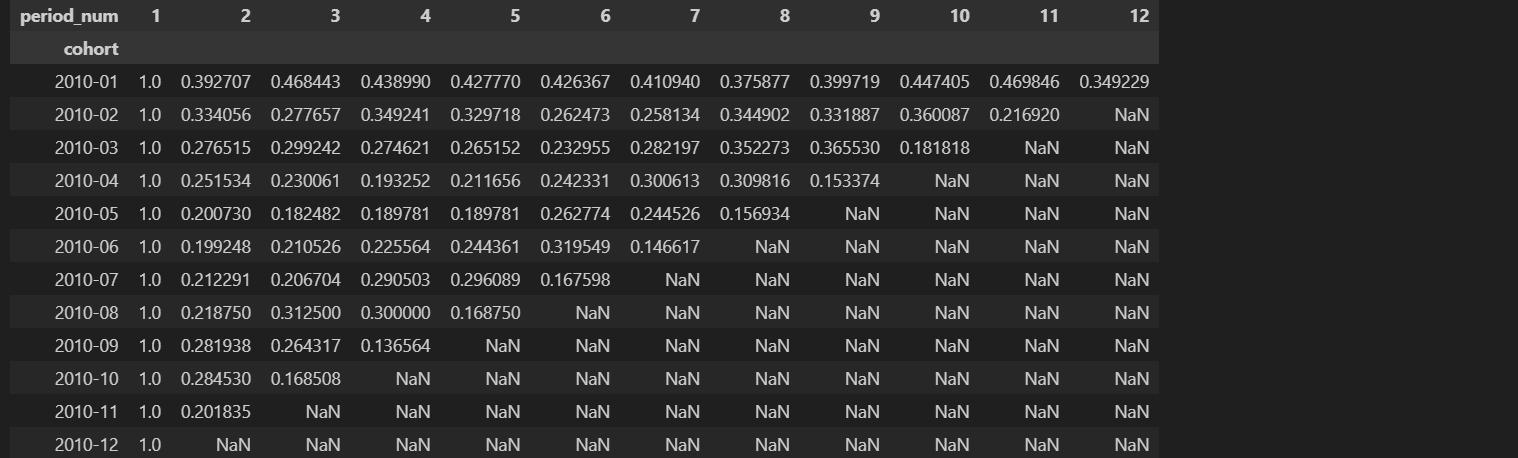
Setelah menghitung nilai retention rate, langkah selanjutnya adalah menampilkan tabel pivot yang menyajikan data tersebut dalam bentuk heatmap. Dengan menggunakan visualisasi heatmap, informasi mengenai retention rate dapat ditampilkan secara lebih intuitif dan menarik. Heatmap akan memberikan gambaran jelas tentang pola retensi pengguna berdasarkan nilai yang ditampilkan dengan gradasi warna, sehingga memudahkan identifikasi area dengan performa tinggi dan rendah dalam hal retensi pengguna. Dengan demikian, analisis ini tidak hanya memberikan angka, tetapi juga visualisasi yang mendukung pemahaman lebih dalam mengenai perilaku pengguna.
with sns.axes_style('white'):
fig, ax = plt.subplots(1, 2, figsize=(12, 8), sharey=True, gridspec_kw={'width_ratios':[1, 11]})
# user retention Analysis cohort
sns.heatmap(df_retention_cohort, annot=True, fmt='.0%', cmap='RdYlGn', ax=ax[1])
ax[1].set_title('User Retention Analysis Cohort')
ax[1].set(xlabel='Month Number', ylabel='')
# cohort size
df_cohort_size = pd.DataFrame(cohort_size)
white_cmap = mcolors.ListedColormap(['white'])
sns.heatmap(df_cohort_size, annot=True, cbar=False, fmt='g', cmap=white_cmap, ax=ax[0])
ax[0].tick_params(bottom=False)
ax[0].set(xlabel='Cohort Size', ylabel='First Order Month', xticklabels=[])
# Set the y-ticklabels for cohort size plot to horizontal
ax[0].set_yticklabels(ax[0].get_yticklabels(), rotation=0)
fig.tight_layout()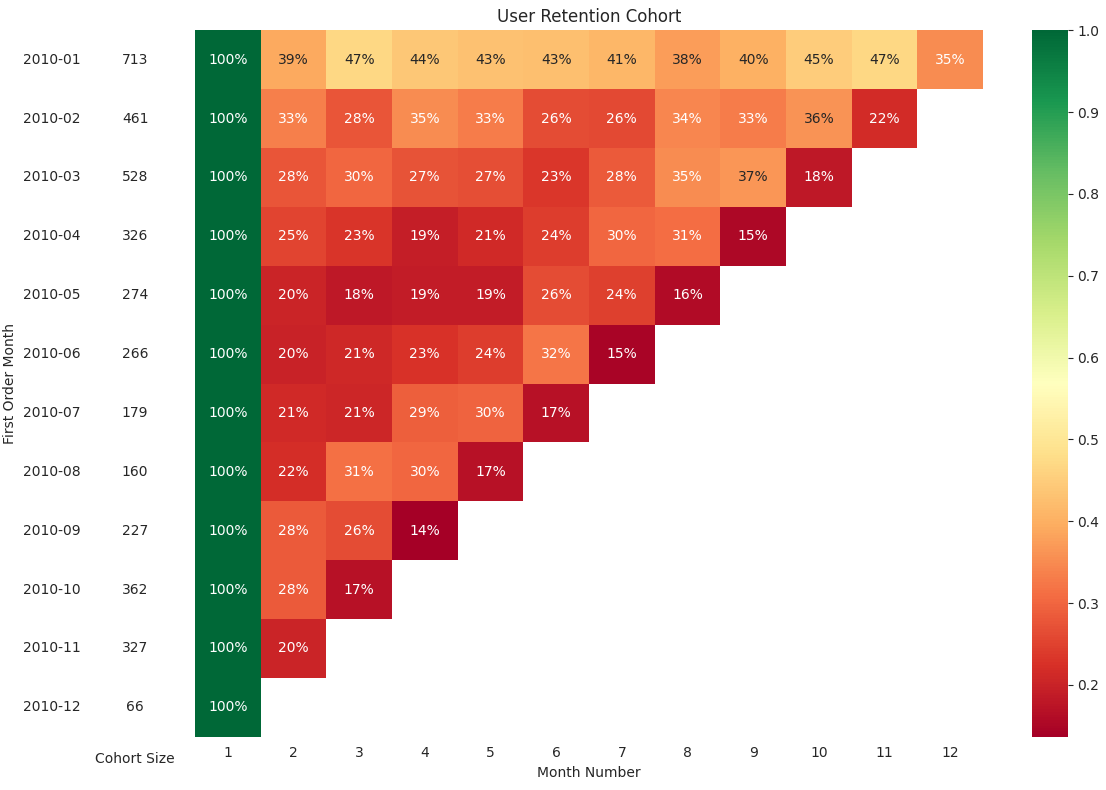
Business Insight
- Pengguna paling banyak pertama kali bertransaksi pada Januari 2010 (713 Pengguna).
- Cohort pengguna tersebut juga yang paling banyak bertransaksi kembali di bulan ke-2 mereka (39% retention rate) dibanding cohort lain.
- Selain itu, cohort tersebut jugalah yang paling loyal bertransaksi selama bulan-bulan berikutnya dengan retention rate ~40%+.
- Sayangnya, sebagian besar pengguna tidak kembali bertransaksi, terlihat dari retention rate di banyak cohort dan bulan yang nilainya tak sampai 50%.
- Yang cukup mengkhawatirkan, retention rate di Desember 2010 menjadi yang terendah untuk semua cohort pengguna dibanding bulan-bulan sebelumnya.